Để biết được thứ cấu trúc này “làm” được những gì, hãy bắt đầu với một ngày thường nhật tại Stack Overflow. Dưới đay là số liệu mỗi ngày từ ngày 9 tháng 2 năm 2016, với số liệu chênh lệch từ ngày 12 tháng 11 năm 2013:
- 209,420,973 (+61,336,090) HTTP requests to our load balancer
- 66,294,789 (+30,199,477) of those were page loads
- 1,240,266,346,053 (+406,273,363,426) bytes (1.24 TB) of HTTP traffic sent
- 569,449,470,023 (+282,874,825,991) bytes (569 GB) total received
- 3,084,303,599,266 (+1,958,311,041,954) bytes (3.08 TB) total sent
- 504,816,843 (+170,244,740) SQL Queries (from HTTP requests alone)
- 5,831,683,114 (+5,418,818,063) Redis hits
- 17,158,874 (not tracked in 2013) Elastic searches
- 3,661,134 (+57,716) Tag Engine requests
- 607,073,066 (+48,848,481) ms (168 hours) spent running SQL queries
- 10,396,073 (-88,950,843) ms (2.8 hours) spent on Redis hits
- 147,018,571 (+14,634,512) ms (40.8 hours) spent on Tag Engine requests
- 1,609,944,301 (-1,118,232,744) ms (447 hours) spent processing in ASP.Net
- 22.71 (-5.29) ms average (19.12 ms in ASP.Net) for 49,180,275 question page renders
- 11.80 (-53.2) ms average (8.81 ms in ASP.Net) for 6,370,076 home page renders
Chắc hẳn bạn đang thắc mắc về sự sụt giảm thời gian xử lý ASP.Net mạnh mẽ so với năm 2013 (hồi đấy là 757 tiếng đồng hồ) mặc dù có đến 61 triệu request mỗi ngày. Đó là nhờ vào một đợt nâng cấp phần cứng hồi đầu năm 2015 cùng với việc tối ưu hiệu năng trong chính bản thân ứng dụng. Đừng quên: hiệu năng vẫn là một tính năng. Nếu bạn đang tò mò về vấn đề phần cứng hơn, đừng lo, tất cả các thắc mắc phần cứng cả bạn sẽ được giải quyết ở phần sau.
Vậy 2 năm qua có gì mới? Bên cạnh việc thay thế một số server và thiết bị mạng, cũng không nhiều. Sau đây là một loạt phần cứng hàng đầu đang chạy trang web mỗi ngày (có ghi rõ khác biệt so với 2013):
- 4 Microsoft SQL Servers (phần cứng mới với 2 trong số đó)
- 11 IIS Web Servers (phần cứng mới)
- 2 Redis Servers (phần cứng mới)
- 3 Tag Engine servers (phần cứng mới cho 2 trên 3)
- 3 Elasticsearch servers (như cũ)
- 4 HAProxy Load Balancers (thêm 2 để hỗ trợ CloudFlare)
- 2 Networks (mỗi bộ gồm Nexus 5596 Core + 2232TM Fabric Extenders, nâng cấp đến 10Gbps mọi chỗ)
- 2 Fortinet 800C Firewalls (thay thế Cisco 5525-X ASAs)
- 2 Cisco ASR-1001 Routers (thay thế Cisco 3945 Routers)
- 2 Cisco ASR-1001-x Routers (mới!)
Chúng tôi cần gì để chạy Stack Overflow? Vẫn chưa quá khác kể từ 2013, nhưng nhờ vào những thao tác tối ưu và phần cứng mới được nhắc đến ở trên, chúng tôi giảm xuống chỉ cần 1 web server duy nhất. Chúng tôi đã (vô tình) test giả thuyết này, và đã thành công (vài lần). Các bạn cần hiểu rõ: tôi chỉ nói là làm được thôi, chứ không nói đây là một ý hay. Nhưng cũng vui mà đúng không?
Sau khi có được các con số gốc để đối chiếu mở rộng, hãy tìm hiểu cách thực hiện những web page màu mè này nhé. Vì có rất ít hệ thống tách biệt hoàn toàn (và của Stack Overfow cũng không ngoại lệ), các quyết định liên quan đến kiến trúc thường chả có tác dụng lớn nếu không nhìn vào toàn cảnh, cách những mãnh ghép nhỏ khớp với chỉnh thể. Đó là mục tiêu của chúng ta, xử lý chỉnh thể. Đây sẽ là bài viết tổng quan về hạ tầng với một số điểm chính trong phần cứng; bài kế tiếp theo sẽ đi chi tiết hơn về vấn đề này.
Sau đây là một số hình ảnh của phần cứng hiện nay, đây là hình ảnh của giá A (nó có một giá chị em tương đồng B nữa):

Kế tiếp, hãy nói về layout. Sau đây là tổng quan logic của các hệ thống lớn hiện nay:

Ground Rules
Sau đây là một số quy luật áp dụng global nên bạn không cần phải lặp lại với mỗi lần setup:
- Mọi thứ đều phải redundant (dư thừa-để dự phòng).
- Mọi servers và trang bị mạng có ít nhất kết nối 2x 10Gbps.
- Mọi servers có 2 luồn nguồn thông qua 2 nguồn điện, từ 2 UPS units được 2 máy phát và 2 utility feeds đảm bảo.
- Mọi servers có liên kết dự phòng giữa giá A và B.
- Mọi servers và dịch vụ phải dư thừa gấp đôi thông qua một trung tâm dữ liệu khác (Colorado), dù trong bài tôi sẽ chủ yếu bàn về New York.
- Mọi thứ đều phải redundant (dự phòng).
The Internets
Bạn phải tìm được chúng tôi trước — đó chính là DNS. Tìm chúng tôi phải nhanh, vậy nên chúng tôi thuê CloudFlare (hiện nay) vì họ có server DNS gần hơn (đếu hầu như… tất cả mọi địa điểm trên thế giới). Chúng tôi cập nhật DNS record thông qua một API, và họ sẽ đảm nhiệm việc “hosting” DNS. Để an toàn hết mức, chúng tôi hiển nhiên vẫn cần DNS server của riêng mình. Nếu tận thế có xảy ra (có khả năng do GPL, Punyon, hoặc caching gây ra) và mọi người vẫn muốn lập trình để khoay khỏa, chúng tôi sẽ bật chúng lên.
Sau khi đã tìm được chỗ ẩn nấu bí mật, HTTP traffic sẽ đến từ một trong bốn ISP (Level 3, Zayo, Cogent, và Lightower ở New York) và đi qua một trong bốn bộ định tuyến biên của chúng tôi. Chúng tôi sẽ tiếp tục peer với ISPs bằng BGP (khá chuẩn mực) để kiểm soát được dòng traffic và cung cấp một vài lối qua rộng cho traffic để có thể đến với chúng tôi thật hiệu quả. Các bộ định tuyến ASR-1001 và ASR-1001-X này được dùng theo cặp, mỗi cặp sẽ phục vụ 2 ISPs theo hướng active/active — vậy ta đã có backup ở đây. Mặc dù chúng đều trên cùng một mạng 10Gbps vật lý, external traffic (truy cập từ bên ngoài) sẽ được đưa vào external VLANs tách biệt, cân bằng tải cũng sẽ được kết nối vào đây. Sau khi đi qua bộ định tuyết, bạn sẽ hướng đến bộ cân bằng tải.
Còn nữa, có lẽ đây là lúc phù hợp để giời thiệu thêm với các bạn rằng chúng tôi có một 10Gbps MPLS giữa hai trung tâm dữ liệu, nhưng lại không trực tiếp tham gia phục vụ cho trang web. Chúng tôi dùng kết nối này để sao lưu dữ liệu và phục hổi nhanh chóng nếu cần. “Nhưng mà này, thế có gì đâu mà redundant!” Ừ thì, bạn cũng đúng về mặt kỹ thuật đấy, đó là điểm thất bại duy nhất. Nhưng khoan đã! Chúng tôi còn duy trì 2 failover OSPF route (MPSL là cái #1, OSPF là cái #2 và #3 tính theo chi phí) qua ISPs của chúng tôi. Mỗi bộ kết nối với bộ tương ứng ở Colorado, và chúng tải traffic cân bằng giữa chúng trong trường hợp failover.
Chú thích: failover là phương thức bảo vệ hệ thống, trong đó, thiết bị dự phòng sẽ thay thế hệ thống chính nếu có sự cố xảy ra.
Load Balancers (HAProxy)
Bộ cân bằng tải đang chạy HAProxy 1.5.15 trên CentOS 7 (phiên bản Linux ưa thích của chúng tôi). TLS (SSL) traffic cũng bị terminate trong HAProxy. Chúng tôi sẽ sớm phải nghiên cứu kỹ về HAProxy 1.7 để hỗ trợ HTTP/2.
Không giống những server khác với liên kết mạng kép 10Gbps LACP, mỗi cân bằng tải có 2 cặp 10Gbps: một cái cho mạng ngoại vi và một cái cho DMZ. Những hộp thiết bị này được trang bị từ 64GB bộ nhớ trở lên để xử lý SSL negotiation thêm hiệu quả. Khi chúng ta có thể cache nhiều session TLS hơn trong bộ nhớ để tái sử dụng, thì hệ thống sẽ ít phải tính toán lại các kết nối sau đó đến cùng một client. Như vậy chúng ta có thể khôi phục lại session nhanh hơn và tiếp kiệm hơn. Vì RAM khá rẻ, nên đây là một lựa chọn dễ dàng.
Bản thân cân bằng tải lại setup càng đơn giản. Chúng tôi listen nhiều IPs của các site khác nhau (đa phần là vì vấn đề certificate và quản lý DNS) và định tuyết đến nhiều backend chủ (master) yếu dựa trên host header. Điểm đáng chú ý nhất mà chúng tôi thực hiện ở đây là rate limiting và một vài header capture (được gửi từ web tier của chúng tôi) vào HAProxy syslog message, từ đó chúng tôi có thể ghi lại thông số hiệu năng cho mỗi request.
Web Tier (IIS 8.5, ASP.Net MVC 5.2.3, and .Net 4.6.1)
Cân bằng tải sẽ mồi traffic đến 9 server mà chúng tôi gọi là “primary” (01-09) và 2 “dev/meta” (10-11, staging environment của chúng tôi) web server. Server chính chạy các nội dung như Stack Overflow, Careers, và tất cả các trang Stack Exchange, ngoài meta.stackoverflow.com và meta.stackexchange.com, chạy trên 2 server cuối cùng.
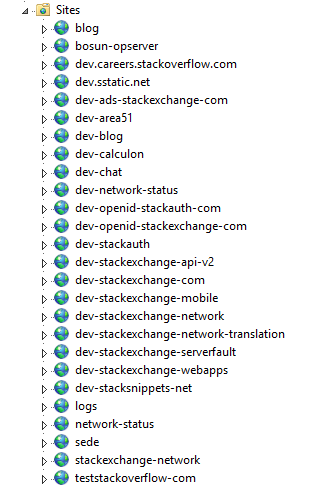
Sau đây là mô hình phân bố của Stack Overflow khắp các web tier trong Opserver (dashboard giám sát nội bộ của chúng tôi):
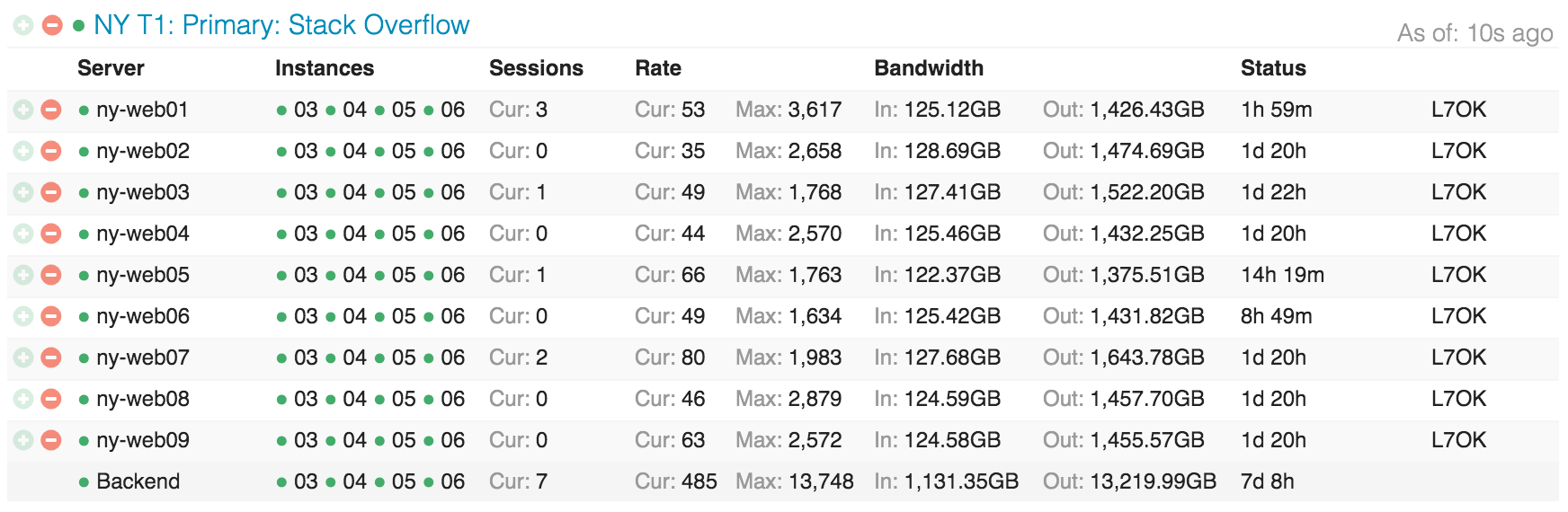
…Và theo cách nhìn ứng dụng, những web server đó sẽ trông như thế này:

Service Tier (IIS, ASP.Net MVC 5.2.3, .Net 4.6.1, and HTTP.SYS)
Đằng sau những web server này là một khái niệm khá giống với “service tier”, cũng chạy IIS 8.5 trên Windows 2012R2. Tier này chạy internal service để hỗ hợ production web tier và các hệ thống nội bộ khác. Hai nhân tố lớn ở đây là “Stack Server”, chạy tag engine và dựa trên http.sys (không sau IIS) và Providence API (IIS-based). Fun fact: tôi phải đặt affinity trên mỗi 2 process này để đổ bộ vào những socket riêng biệt vì Stack Server chỉ steamrolls L2 và L3 cache khi refresh list câu hỏi mỗi 2 phút.
Những hộp service này thực hiện tác vụ nặng nề với tag engine và backend APIs tại nơi chúng tôi cần redundancy, nhưng không đến 9x redundancy. Ví dụ, việc load tất cả post và tag của chúng (thay đổi mỗi n phút) từ database (hiện là 2) không phải là ít. Chúng tôi không muốn phải thực hiện 9 lần tải như vậy trên web tier; 3 lần là đã đủ, và đồng thời cũng khá an toàn. Chúng tôi cũng thiết đặt những hộp này khác đi ở phía phần cứng để tối ưu tốt hơn cho các đặc tính load điện toán khác nhau của tag engine và indexing jobs (cũng chạy ở đây). “Tag engine” là một chủ đề tương đối phức tạp và sẽ có một post riêng. Về cơ bản: khi bạn truy cập /questions/tagged/java, bạn sẽ tìm đến tag engine để xem được câu hỏi nào trùng khớp. Nó sẽ đảm nhiệm mọi công việc đối chiếu tag của chúng tôi ngoài /search. nên new navigation,… tất cả đều đang dùng data service này.
Cache & Pub/Sub (Redis)
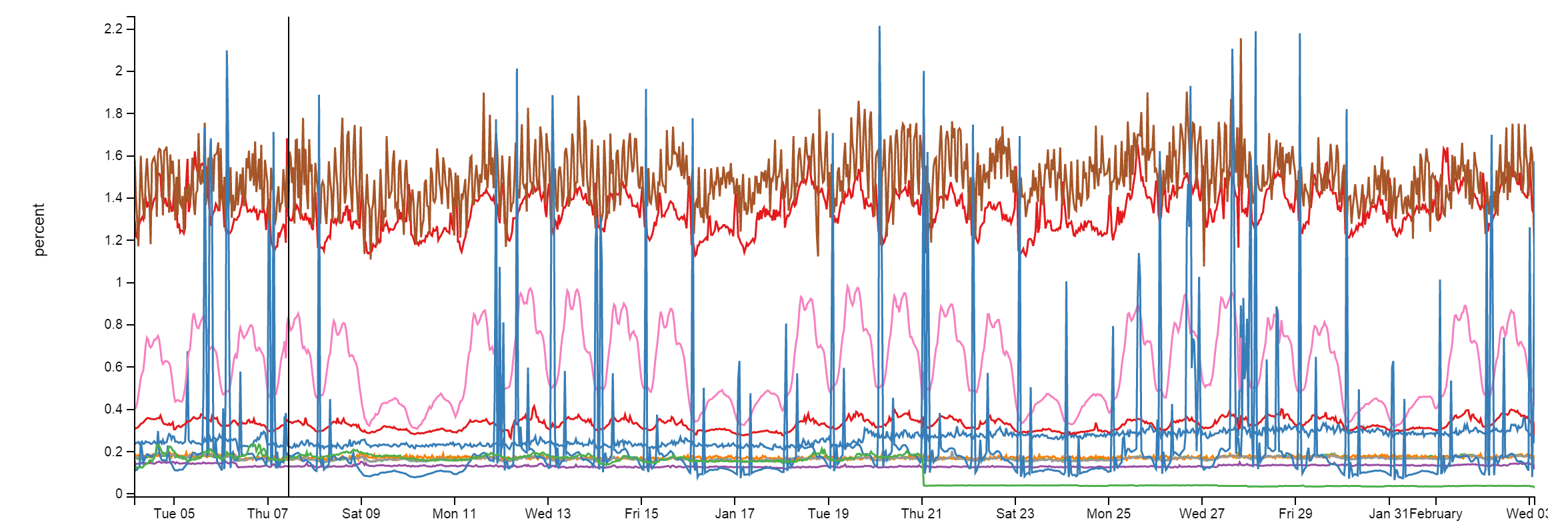
Chúng tôi dùng Redis cho một số vấn đề ở đây, và hiệu quả rất ổn định. Mặc dù phải xử lý khoảng 160 tỷ ops một tháng, mỗi instance đều dưới 2% CPU. Thường thấp hơn nhiều:
Chúng tôi có một cache system L1/L2 với Redis. “L1” là HTTP Cache trên web server hoặc bất cứ ứng dụng nào đang chạy. “L2” quay trở lại Redis và truy xuất giá trị ra. Giá trị của chúng tôi được lưu trữ trong Protobuf format, thông qua protobuf-dot-net bởi Marc Gravell. Với một client, chúng tôi đang dùng StackExchange.Redis — tự viết, nguồn mở. Khi một web server nhận một cache miss ở cả L1 và L2, nó sẽ truy xuất giá trị từ nguồn (database query, API call,…) và đặt kết quả vào cả local cache và Redis. Server tiếp theo muốn lấy giá trị có thể bỏ qua L1, nhưng sẽ tìm thấy giá trị trong L2/Edis, không cần đến database query hoặc API call.
Chúng tôi cũng chạy nhiều trang Q&A, vậy nên mỗi site sẽ có L1/L2 caching riêng: theo key prefix trong L1 và theo database ID trong L2/Redis.
Bên cạnh hai Redis server chính (master/slave) chạy tất cả site instance, chúng tôi còn có một machine learning instance làm slave cho cả 2 server chuyên biệt hơn (do vấn đề bộ nhớ). Machine learning instance này được sử dụng để giới thiệu câu hỏi lên home page, dối chiếu job tốt hơn,… Đó là platform tên gọi là Providence, do Kevin Montrose giới thiệu ở đây.
Server chính của Redis có 256GB RAM (khoảng 90GB được sử dụng) và server Providence có đến 384GB RAM (khoảng 125GB được sử dụng).
Tuy vậy, Redis không chỉ cho cache, nó còn có một cơ chế publish & subscriber trong đó một server có thể publish message và tất cả subscriber sẽ nhận nó—kể cả downstream client trên Redis slave. Chúng tôi sử dụng cơ chế này để dọn sạch L1 cache trên các server khác khi một web server thực hiện removal để nhất quán hơn, nhưng vẫn còn một cách dùng rất hay nữa: websocket.
Websockets (NetGain)
Chúng tôi sử dụng websocket để push cập nhật thời gian thực đến người dùng như notification trên top bar, vote counts, new nav counts, câu trả lời và comment mới, và nhiều thông tin khác.
Bản thân socket server sử dụng raw socket chạy trên web tier. Đây là một ứng dụng nhỏ gọn chạy trên nền thư viện nguồn mở: StackExchange.NetGain. Lúc đỉnh điểm, chúng tôi có khoảng 500.000 websocket mở đồng thời. Đó là con số trình duyệt đáng sợ. Fun fact: một số trình duyệt đã được mở hơn 18 tháng rồi, chúng tôi cũng chả rõ lý dó. Ai đó nên kiểm tra thử xem mấy developer này còn sống hay không. Sau đây là số websocket được mở đồng thời trong tuần:
Tại sao là websocket? Với quy mô của chúng tôi, chúng cực kỳ hiệu quả hơn polling. Với hướng đi này, chúng tôi có thể push data đơn giản hơn với ít tài nguyên hơn, đồng thời có thể cập nhật nhanh nhạy hơn với user. Dù vậy, vẫn có một số vấn đề—như ephemeral port và file handle exhaustion trên cân bằng tải.
Search (Elasticsearch)
Spoiler: phần này cũng chả quan trọng lắm. Web tier thực hiện vanilla searches (vanilla: chuẩn, ít tùy biến) đối với Elasticsearch 1.4, dùng StackExchange.Elastic client. Khác với các khoảng khác, chúng tôi không có kế hoạch open source tài nguyên này đơn giản vì nó chỉ thể hiện một subset rất nhỏ của API mà chúng tôi sử dụng, nên công khai như vậy sẽ hại hơn là lợi. Chúng tối sử dụng elastic cho /search, tính toán các câu hỏi liên quan, và gợi ý khi hỏi câu hỏi.
Mỗi cụm Elastic (luôn có cụm elastic trong mỗi data center) có 3 node, và mỗi site có index riêng. Careers có thêm một số index. Một số điểm đặc biệt trong thế giới elastic: 3 cụm server của chúng tôi có một chút “hầm hố” hơn với tất cả lưu trữ là SSD, 192GB RAM, và 10Gbps network kép cho mỗi cụm.
Cùng các miền ứng dụng (yeah, chúng tôi tiêu tùng với .NetCore ở đay rồi…) trong Stack Server host tag engine cũng liên tục index item trong Elasticsearch. Chúng tôi thực hiện một số thủ thuật ở đây như ROWVERSION trong SQL Server (nguồn data) so với “last position” document trong Elastic. Vì nó hoạt động như sequence (dãy), chúng ta chỉ việc grab và index bất kỳ item nào thay đổi kể từ lần pass trước đó.
Khả năng mở rộng và khả năng xác định tiền chính xác hơn, là lý do chính chúng tôi dùng Elasticsearch thay vì các tài nguyên như SQL full-text search. SQL CPUs tương tối đắt đỏ, và hiện nay Elastic rẻ hơn và có nhiều tính năng hơn. Vậy tại sao lại không dùng Solr? Chúng tôi muốn tìm kiếm khắp cả network (nhiều index cùng một lúc), và tính năng này vẫn chưa được hỗ trợ lúc chúng tôi cân nhắc. Lý do chúng tôi chưa lên 2.x là vì thay đổi lớn đến “types” có nghĩa rằng chúng tôi cần phải index lại mọi thứ để nâng cấp, và chúng tôi vẫn chưa có nhiều thời gian để làm việc này.
Databases (SQL Server)
Chúng tôi đang sử dụng SQL Server làm single source of truth. Tất cả data trong Elastic và Redis đến từ SQL Server. Chúng tôi chạy 2 cụm SQL Server với AlwaysOn Availability Groups. Mỗi cụm này có 1 master (tiếp nhận hầu như tất cả tải) và 1 bản sao tại New York. Đồng thời, họ có một bản sao tại Colorado (DR center của chúng tôi). Tất cả bản sao đều không đồng bộ.
Cụm đầu tiên là một bộ server Dell R720xd, mỗi server với 384GB RAM, 4TB PCIe SSD space, và 2×12 lõi. Server này host Stack Overflow, Sites (đặt tên dở, tôi sẽ giải thích sau), PRIMZ, và Mobile database.
Cụm thứ hai là một bộ server Dell R730xd, mỗi server được trang bị 768GB RAM, 6TB PCIe SSD, và lõi 2×8. Cụm này chạy mọi thứ khác, có thể kể đến Careers, Open ID, Chat, our Exception log, và tất cả các trang Q&A khác (như Super User, Server Fault,…).
Chúng tôi cũng muỗn giữ tuần suất sử dụng CPU trên database tier cho thật thấp, nhưng thực tế hiện nay lại khá cao vì một số vấn đề với plan cache chúng tôi đang cố gắng xác định. Đến giờ phút này, NY-SQL02 và 04 là master, 01 và 03 là các bản sao mới được khởi động lại trong quá trình thực hiện một số cập nhật lên SSD. Đây là thông tin trong 24 giờ qua:

Cách chúng tôi dùng SQL khá đơn giản. Và đơn giản thì sẽ nhanh. Tuy một số queries có thể trở nên khá điên rồ, nhưng bản thân tương tác của chúng tôi với SQL lại khá đơn giản. Chúng tôi có một số legacy Linq2Sql, nhưng tất cả khâu lập trình mới đây đều dùng Dapper, Micro-ORM nguồn mở của chúng tôi dùng POCOs. Nói cách khác: Stack Overflow chỉ có một procedure duy nhất được lưu trữ trong database và tôi dự định sẽ chuyển dấu tích cuối cùng này thành code.
Libraries
Cuối cùng, tôi sẽ thử chuyển thiết bị của chúng tôi thành các thông tin có thể thực sự giúp ích cho các bạn. Dưới đây là danh sách các thư viện .Net nguồn mở chúng tôi liên tục duy trì để các bạn có thể sử dụng thoải mái. Lý do chúng tôi mở nguồn những thư viện này là vì chúng không mang giá trị kinh doanh cố lõi nhưng lại ích lợi cho cộng đồng (nên đừng lo nghĩ nhé):
- Dapper (.Net Core) – Micro-ORM hiệu năng cao cho ADO.Net
- StackExchange.Redis – Redis client hiệu năng cao
- MiniProfiler – Profiler gọn nhẹ được chúng tôi chạy ở mọi trang (cũng có hỗ trợ Ruby, Go, và Node)
- Exceptional – Error logger cho SQL, JSON, MySQL,…
- Jil – JSON (de)serializer hiệu năng cao
- Sigil – .Net CIL generation helper (cho trường hợp C# không đủ nhanh)
- NetGain – Websocket server hiệu năng cao
- Opserver – Dashboard theo dõi, kiếm soát trực tiếp hầu hết hệ thống và lấy thông tin từ Orion, Bosun, hoặc WMI.
- Bosun – Hệ thống theo dõi backend, viết bằng Go
Techtalk via nickcraver