Gần đây do đi làm phải code sml nên mình cũng hơi lười viết bài chuyên sâu về technical. Tuy vậy, mình cảm thấy lâu rồi không viết tutorial kĩ thuật nên hôm nay viết lại cho khỏi lụt nghề nhé.
Kì này, chúng ta sẽ cùng làm trò với thư viện Puppeteer của NodeJS, một thư viện cho phép chạy Chrome dưới chế độ headless browser. Bài viết sẽ gồm 3 phần:
- Phần 1: Làm quen với puppeteer.
- Phần 2: Dùng puppeteer để cào dữ liệu mương14 và webtretho.
- Phần 3: Viết Automation test với puppeteer
Trước khi bắt đầu vào code thì chúng ta tìm hiểu sơ chút lý thuyết trước nha.
Headless browser là gì? Làm được trò gì?
Muốn biết Puppeteer làm được trò gì, ta phải hiểu về khái niệm Headless browser – dịch cho vui là browser không đầu, tức là browser chạy mà không cần giao diện.
Ủa chạy browser không cần giao diện để làm chi vậy? Đôi khi chúng ta sẽ cần mở browser lên không phải để … duyệt web, mà là cào dữ liệu, để test, chụp screenshot, đo performance.
Ta muốn làm những chuyện này trên các server Linux, docker v…v không có giao diện. Lúc này, headless browser là lựa chọn duy nhất.
Các bạn có thể tìm hiểu thêm ở đây: https://en.wikipedia.org/wiki/Headless_browser

Puppeteer là cái chi chi?
Puppeteer là một thư viện của NodeJS, có khả năng điều khiển Chrome headless browser thông qua code. Các bạn có thể tìm hiểu thêm tại: https://github.com/GoogleChrome/puppeteer
Do vậy, Chrome làm được gì thì Puppeteer làm được cái đấy. Ta có thể dùng NodeJS + Puppeteer để làm nhiều trò hay ho như chụp ảnh màn hình, thu thập dữ liệu, chạy automation test.
Trang Github của puppeteer
Crawl dữ liệu bằng headless browser có gì vui?
Trước đây mình đã có 1 bài về trsich xuất dữ liệu với HTML Agility Pack. Tuy nhiên, cách này có một số khuyết điểm sau:
- Chỉ lấy được HTML thuần của trang web. Ngày xưa thì còn ok chứ bây giờ hầu hết các trang đều dùng JavaScript và Ajax để lấy dữ liệu và render. Lấy HTML thuần thì ta không chôm được gì cả.
- Bên server có một số biện pháp để chặn HTTP Request đơn thuần ( dựa theo user-agent, …) nên dễ bị chặn.
- Với một số trang phải đăng nhập mới có dữ liệu, việc quản lý cookie, đăng nhập v…v với HTML Agility Pack rất rắc rối.
Dùng Headless browser, ta giải quyết được toàn bộ những vấn đề trên. Đến cả Google còn sử dụng headles browser để crawl các trang web dùng Ajax cơ mà.

Chuẩn bị đồ nghề
Lý thuyết đủ rồi, giờ chúng ta chuẩn bị đồ nghề nào để bắt tay vào code nào
IDE: Với NodeJS, ta dùng Visual Studio Code là nhẹ và tiện nhất vì có thể dễ dàng debug. VS Code nhẹ lại free, chạy được trên cả Win lẫn Mac nên các bạn tải về dùng nha: https://code.visualstudio.com/
Nếu khả năng trâu bò hơn thì các bạn cứ dùng Notepad ++ hoặc Sublime Text đều được
NodeJS: Để cài NodeJS, các bạn vào https://nodejs.org/en/download/ nhé. Có thể dùng bản 8.9.1 hoặc 9.2 đều ok.
Nếu máy của bạn dùng NodeJS bản cũ hơn thì nên update lên để có thể dùng async/await trong JavaScript, code sẽ trong sáng hơn nhìu.
Khởi tạo project
- Tạo 1 thư mục mang tên puppeteer-test
- Các bạn mở cửa sổ cmd trong thư mục này, gõ npm init, sau đó cứ enter ok hết để khởi tạo project nodejs
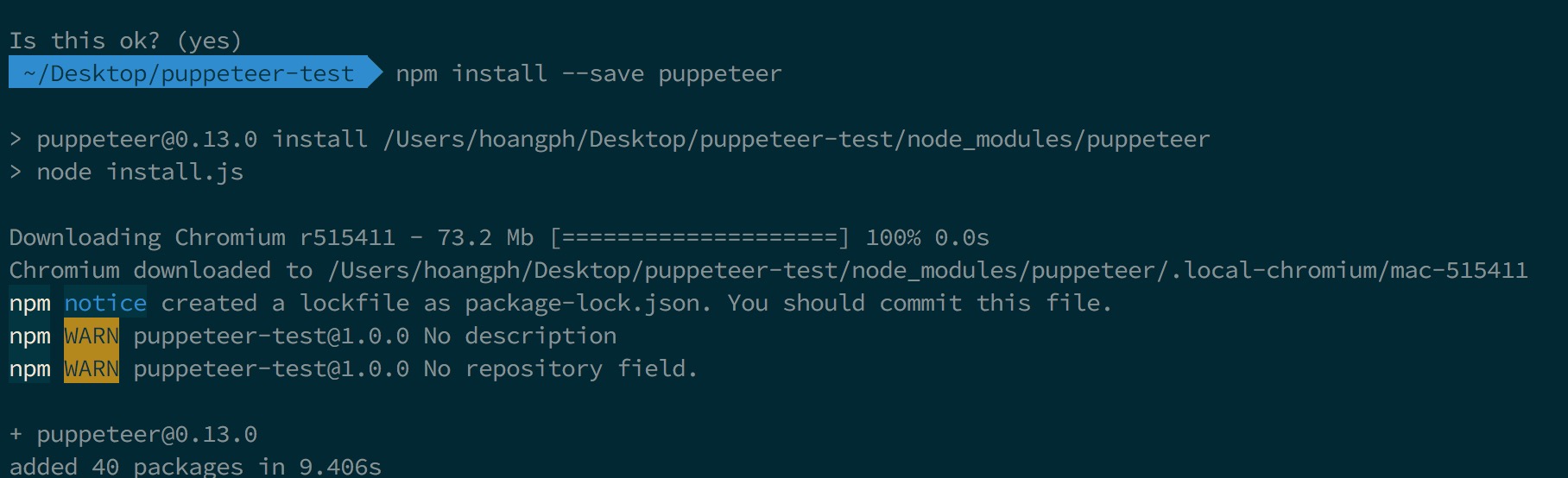
- Tiếp tục gõ npm install –save puppeteer để cài puppeteer. npm sẽ tải luôn bản Chrome mới nhất khoảng 100MB nên có thể hơi lâu nhé (xem hình minh hoạ dưới).
npm install --save puppeteer

4. Mở Visual Studio code hay Nodepad++ cũng được, gõ đoạn code sau vào và save lại thành file index.
5. Từ cửa sổ cmd, gõ node index. Bạn sẽ thấy Chrome mở lên, sau đó đóng, chụp được file ảnh trang web kenh14.vn
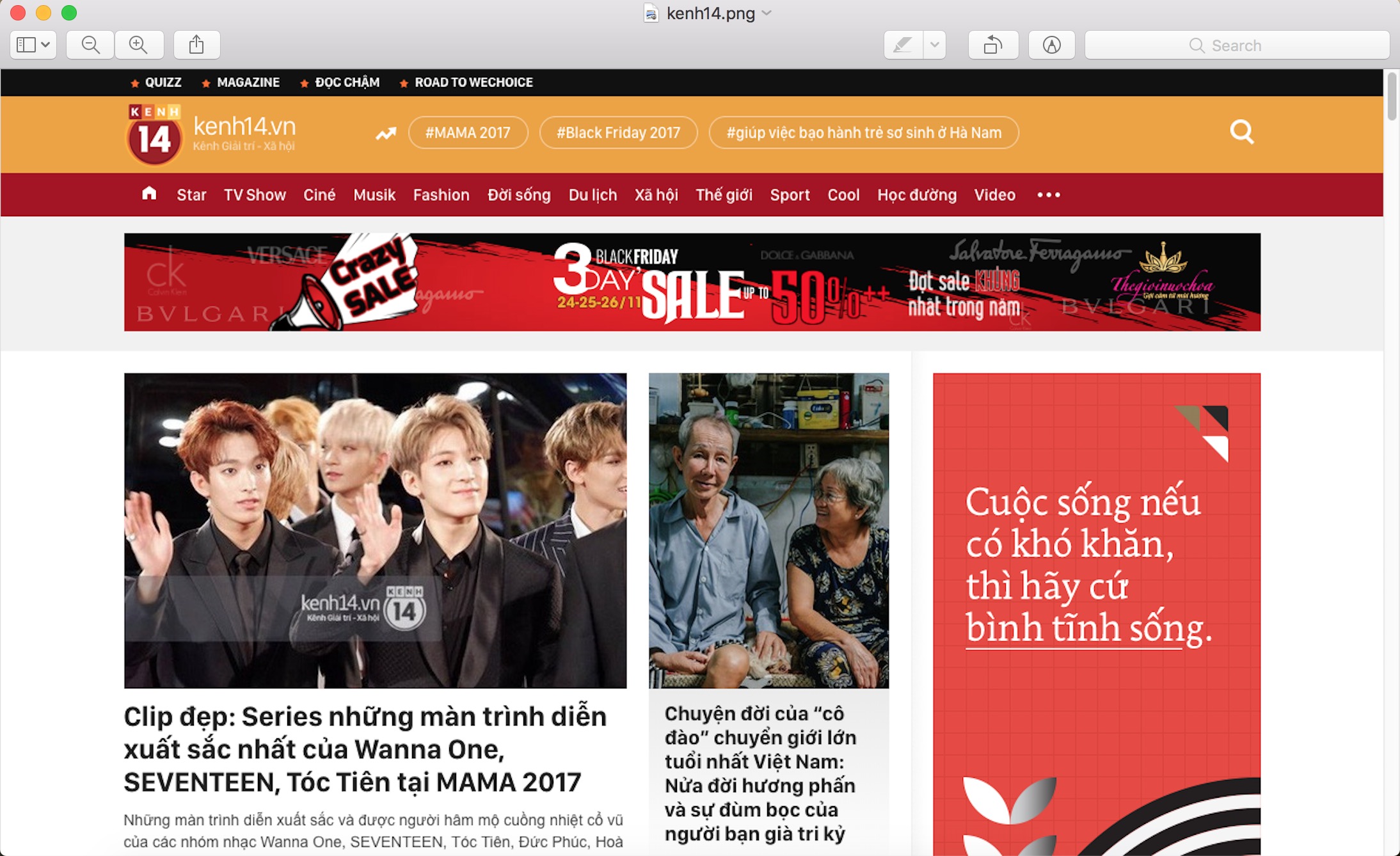
Thành quả của đoạn code trên, hay ghê chưa
Tạm kết
Vậy là các bạn đã chuẩn bị sẵn sàng đồ nghề cho hành trình tiếp theo rồi đấy. Ở phần sau, mình sẽ giới thiệu về API của Puppeteer, sau đó chúng ta sẽ cùng cào dữ liệu từ kenh14 về để làm kênh 15 nhé.
Các bạn có thể đọc trước về API của Puppeteer để chuẩn bị nhe: https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md