Chào mừng các bạn đã quay lại với series Phản Phác Quy Chân. Lần này series sẽ tập trung giải thích mổ xẻ tất tần tật về Unicode, encode và charset. Hầu hết các ngôn ngữ/framework đều hỗ trợ sẵn Unicode nên bạn có thể thoải mái code cả mấy năm trời mà chẳng cần quan tâm đến 2 thằng này. Tuy nhiên, không phải hù gì các bạn nhưng mà “Lỗi liên quan tới encoding là những lỗi khó chịu và khó sửa nhất”, do đó tự trang bị những kiến thức “xưa mà không cũ” về Encoding vẫn khá là cần thiết đấy nhé.
“So I have an announcement to make: if you are a programmer working in 2003 and you don’t know the basics of characters, character sets, encodings, and Unicode, and Icatch you, I’m going to punish you by making you peel onions for 6 months in a submarine. I swear I will.”
And one more thing:
IT’S NOT THAT HARD.
Chuyện ngày xưa ngày xưa
Ngày xửa ngày xưa, từ cái thời Unix và ngôn ngữ C mới ra đời, lưu trữ string là chuyện khá đơn giản. Các máy tính lưu trữ dữ liệu dưới dạng byte, 1 byte gồm 8 bit, lưu trữ được 2^8=256 các giá trị khác nhau. Thuở ấy, vì chỉ lưu trữ mỗi kí tự tiếng Anh, người đời dùng bảng mã ASCII, mỗi kí tự được mã hóa bằng 1 con số từ 32 tới 127 (A là 65, a là 97). Các số từ 1 tới 31 dùng để mã hóa các kí tự đặc biệt, hoặc một số mã lệnh cho CPU.
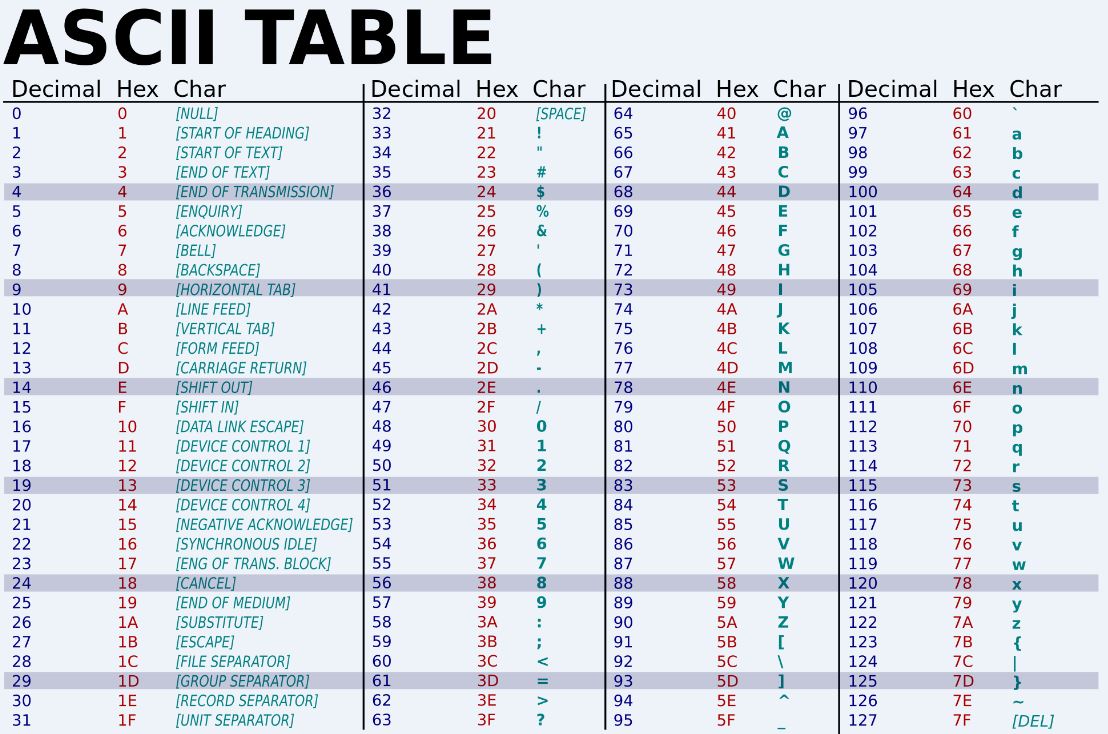
Các cụ có câu “Phú quý sinh lễ nghĩa“. Lưu trữ được tới tận 256 giá trị mà chỉ dùng có 127 thì phí quá, nên phải nhét thêm cái khác vào (Đời nó vốn thế, cứ thấy cái lỗ trống trống là người đời lại muốn tìm cái gì đó mà nhét vào). Thế là các bác lại sử dụng các giá trị từ 128 tới 255 để lưu trữ các kí tự khác. Khốn nạn thay, thằng nào cũng muốn nhét, nhưng mỗi thằng lại nhét một kiểu khác nhau. Các anh Mỹ khoai to thì nhét vào hầm bà lằng mấy kí tự đặc biệt, các anh Ấn Độ khoai ngắn thì lại nhét chữ Ấn Độ vào. Ví dụ, chữ é được mã hóa bằng số 130 ở các hệ điều hành Mẽo, qua Israel lại bị biến tướng thành chữ ![]() , vì bọn Isarel dùng số 130 để mã hóa chữ này.
, vì bọn Isarel dùng số 130 để mã hóa chữ này.
Để tránh tình trạng nhầm lẫn này, các cụ đã thống nhất với nhau, 127 số đầu sẽ tương tự nhau ở toàn bộ các ngôn ngữ. Mỗi hệ thống khác nhau sẽ có cách sử dụng các giá trị từ 128-255 khác nhau, được gọi là code page. Như trong hình, bọn Ả Rập dùng các giá trị từ 128-255 để mã hóa đống giun dế loằng ngoằng của tụi nó, ta phải sử dụng code page này để dịch các giá trị đã mã hóa sang tiếng Ả Rập lại.
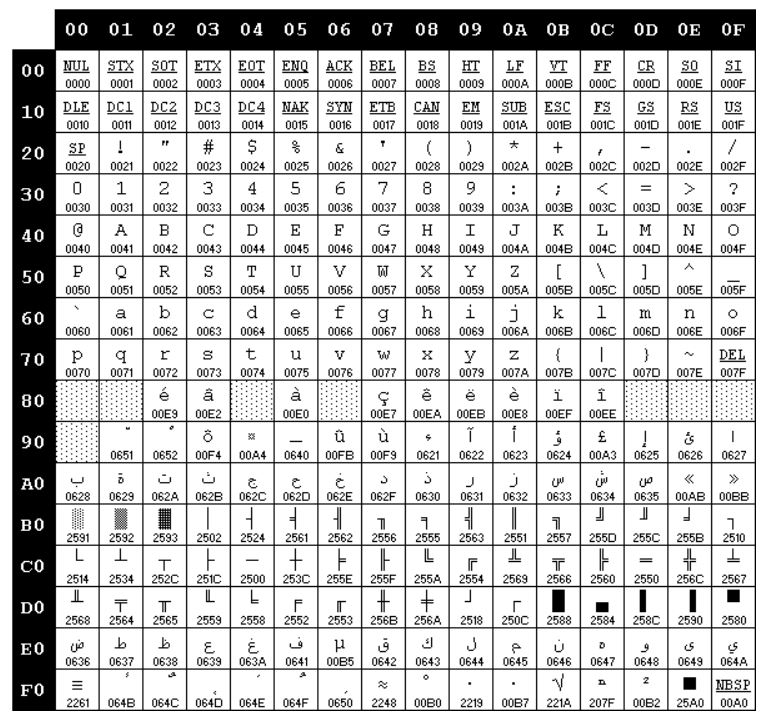
Chuyện đâu phải đã xong. Các anh châu Á nghèo nghèo cũng bắt đầu học đòi dùng máy tính, thế nên phải có cách để mã hóa ngôn ngữ của các ảnh. Mà ngôn ngữ của bọn Á vừa dài vừa nhiều kí tự, điển hình là bọn Tàu và Nhật có tới cả ngàn Hán Tự, chỉ 256 giá trị thì mã hóa thế *éo nào được, do đó ta phải dùng tới 2 byte, tức là 16 bits (Câu “Hàng thì nhỏ mà bộ nhớ thì to” cũng bắt nguồn từ đây). Lắm chuyện rắc rối lại diễn ra.
Bọn developer tự an ủi nhau rằng: kệ mẹ nó, mỗi máy chỉ cần mã hóa kí tự 1 kiểu thôi, chả sao. Thế rồi vào một ngày đẹp trời, ai đó phát minh ra cái Internet, các máy tính kết nối với nhau, tiếng Tàu encode kiểu Tàu, tiếng việt encode kiểu Việt, bao nhiêu rắc rối lại nảy sinh. May thay, Unicode ra đời.
Unicode ngang trời xuất thế
Nói dễ hiểu, Unicode là một bảng mã (Bảng mã này lưu trữ toàn bộ các kí tự trên thế giới), không phải là một cách mã hóa. Nhiều người lầm tưởng rằng mã hóa dạng Unicode tức là dùng 16 bit để mã hóa kí tự, nên có tổng cộng 2^16= 65,536 ký tự, điều này là hoàn toàn sai nhé. Unicode là một bảng mã, mỗi kí tự sẽ được map với một code point trên bảng mã đó. Ví dụ như, chữ A có code point là U+0048 (U là Unicde, 0048 là số dạng hex). Với chuỗi “Hello”, ta sẽ mã hóa ra chuỗi code-point là “U+0048 U+0065 U+006C U+006C U+006F”.
Những tưởng, với bảng mã chung Unicode, mọi vấn đề đã được giải quyết. Từ đây non sông quy về một mối, muôn kiếp thái bình. Thế nhưng đời *éo như mơ, giang hồ vẫn loạn vì mỗi người lại có 1 cách khác nhau để mã hóa và lưu trữ chuỗi code-point này. Vấn đề lại tiếp tục nảy sinh.
Hỡi thế gian charset là gì, mà bọn dev vỡ đầu sống chết
Ban đầu, người ta cho rằng có thế sử dụng 2 byte để biểu thị một code point. Chuỗi 5 code point phía trên sẽ được biểu diễn bằng 10 byte sau “00 48 00 65 00 6C 00 6C 00 6F”, cách này còn gọi là UTF-16. Thế rồi, người đời cũng có câu “Bần cùng sinh đạo tặc”, các anh Mĩ nhà nghèo, thấy mã hóa kiểu UTF-16 hơi bị dư bộ nhớ (Mấy số rõ 00 là dư thừa), nên chế ra kiểu UTF-8, chỉ dùng 8 bit.
WTF, 8 bit thì làm sao mà lưu? Các anh ấy lưu theo kiểu “dùng tới đâu lấy tới đó”. Với các kí tự tiếng Anh, chỉ dùng 8 bit (1 byte) để lưu trữ, với các kí tự khác (1 byte không đủ để lưu) thì sử dụng 2, 3 byte để lưu trữ. Trớ trêu thay, nhiều thằng nhà giàu dư hơi lại nghĩ ra thêm kiểu UTF-32,dùng tới tận 4 byte cho một kí tự. Các kiểu UTF-8, UTF-16, UTF-32 hay ISO 8859-1 còn được gọi là Charset.
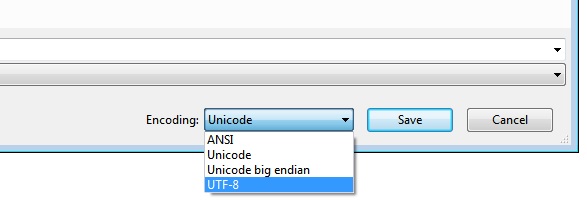
Một câu hỏi được đặt ra! Nếu Unicode chỉ là 1 bảng mã, vậy tại sao trong các ngôn ngữ lập trình, thư viện, người ta lại có Encoding kiểu Unicode ??? Đây thật ra là một chiêu “tung hỏa mù” nhầm lừa gạt những thằng không biết gì về encoding. Thông thường, các hệ điều hành hay sử dụng charsetUTF-16 để mã hóa Unicode, do đó Unicode ở đây thường tương đương với UTF-16 nhé. VD như khi bạn lưu file trong Notepad, Unicode ở đây chính là UTF-16 đó.
Bài học rút ra
Khi nhận được một chuỗi bit, nếu không biết chuỗi này được Encode theo dạng gì, hệ thống sẽ hiển thị sai và ra những dấu ????. Vào các trang tiếng Nhật ngày xưa sẽ thấy, vì bọn này sử dụng SHIFT-JIS để encode nên Internet Explorer không thể hiển thị được. Ngày nay, các trang web thường đính kèm sẵn charset trong thẻ meta hoặc header của response, do đó mọi ngôn ngữ có thể hiển thị bình thường hơn.
 Bài học rút ra là gì? Khi lập trình, nếu cần hiển thị, lưu trữ tiếng Việt (trên Web, dưới database, …) cứ chọn Unicode hoặc UTF-8 mà táng thôi. Nếu Web không hiển thị đúng tiếng Việt thì nhớ chọn đúng font, thêm charset vào header hoặc meta tag là được. Đơn giản vậy thôi nhé, chào thân ái và quyết thắng.
Bài học rút ra là gì? Khi lập trình, nếu cần hiển thị, lưu trữ tiếng Việt (trên Web, dưới database, …) cứ chọn Unicode hoặc UTF-8 mà táng thôi. Nếu Web không hiển thị đúng tiếng Việt thì nhớ chọn đúng font, thêm charset vào header hoặc meta tag là được. Đơn giản vậy thôi nhé, chào thân ái và quyết thắng.
Topdev via toidicodedao