Giới thiệu
Gần đây thấy bản thân chém gió rất nhiều về MapReduce, Hadoop v.v nhưng chưa thấy có bài viết nào tổng hợp + giải thích cụ thể về MapReduce vì vậy mình quyết định viết một bài Chém gió về Map-Reduce. Bài viết này sẽ giới thiệu 3 vấn đề sau:
- Distributed File-System – DFS (Hệ thống file phân tán)
- Mô hình tính toán MapReduce
- Lập lịch và luồng dữ liệu
Vấn đề với năng lực xử lý của một máy tính
Máy tính mà chúng ta vẫn sử dụng để xử lý dữ liệu hàng ngày có thể được mô tả một cách trừu tượng hoá nhất bằng hình vẽ dưới đây.
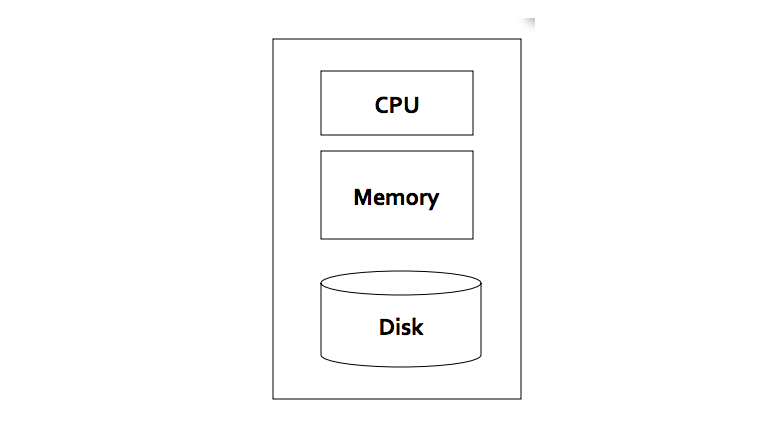
Theo như hình vẽ chúng ta có: CPU, Memory và đĩa cứng. Theo công nghệ hiện tại mình biết thì mỗi module có các thông số tối đa như sau (dòng máy chủ phổ thông):
- CPU: với máy tính thông thường thì trên 1 board chỉ có 1 đến 2 CPUs. Mỗi CPU có thể có tối đa 18 cores (theo công nghệ hiện tại mình biết)
- Memory: trên 1 mainboard có thể cắm tối đa 16 thanh RAM. Mỗi thanh có dung lượng tối từ 8G. Một máy tính có thể có khoảng 8* 16 = 128GB RAM)
- Đĩa cứng: dung lượng tối đa của HDD theo công nghệ hiện tại mình biết là 8TB
Với máy tính với cấu hình dù rất khoẻ như ở trên thì ta vẫn thấy giới hạn xử lý dữ liệu của nó. Cụ thể máy tính không thể lưu trữ được quá 8TB dữ liệu, không thể đồng thời xử lý được dữ liệu lớn hơn 128GB (kích thước của RAM) và không thể đồng thời xử lý được lớn hơn 18 luồng chương trình.
Trong khi đấy thực tế lại dữ liệu lại đến với số lượng nhanh và nhiều hơn dung lượng có thể xử lý bởi một máy tính rất nhiều. Ví dụ điển hình nhất là Google (dù rằng sẽ có người tranh luận rằng chả ai có dữ liệu nhiều như Google). Theo Google họ có rất nhiều dữ liệu:
- 10 tỉ trang web
- Trung bình kích thước 1 trang web: 20KB → 10 tỉ * 20KB == 200TB
- Tốc độ đọc của đĩa cứng là 50MB/giây → thời gian để đọc 200TB là 4 triệu giây ~ 46+ ngày.
Do vậy chưa tính đến việc xử lý dữ liệu, chỉ riêng việc đọc dữ liệu đã vượt qua năng lực xử lý của 1 máy tính. Điều này đòi hỏi một mô hình truy vấn dữ liệu mới cho phép xử lý lượng dữ liệu trên. Mô hình tính toán Cluster và Distributed File System ra đời do đòi hỏi thực tế này.
Giải quyết bài toán một máy tính thế nào?
Như đã tính toán thử ở trên, một máy tính không thể nào xử lý được số lượng dữ liệu lớn như vậy. Điều này dẫn đến 2 đòi hỏi:
- Đấu nối nhiều máy tính để cùng xử lý
- Tìm ra cách để cho các máy tính cùng xử lý
Đấu nối (GFS)
Theo như bài viết trên trang DataCenterKnowledge thì năm 2011 Google có hơn 1 triệu máy tính! Vậy họ giải quyết vấn đề đấu nối máy tính kiểu gì?
Dưới đây là một phương pháp:
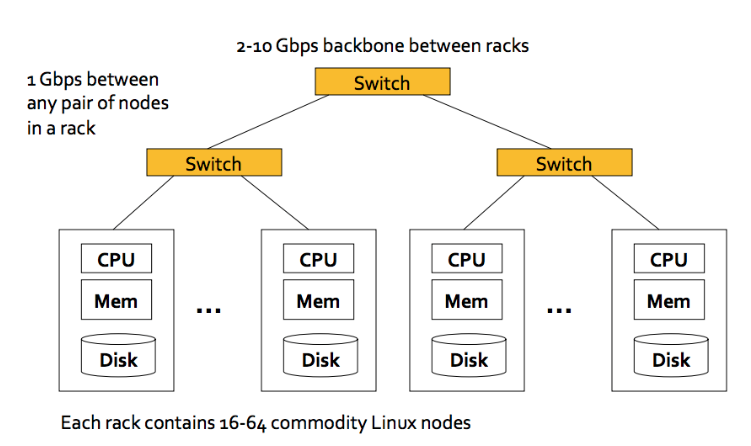
- Mỗi rack trong Data Center có một cơ số máy tính (từ 16 → 64 máy tính với cấu hình phổ thông)
- Các máy tính được kết nối với nhau bằng 1Gbps Switch
- Các Rack được kết nối với nhau bằng Switch 2-10Gbps
Nhờ kiến trúc này ta có thể đấu nối được nhiều máy chủ với nhau. Bài toán đấu nối được giải quyết. Tuy vậy, số lượng máy chủ nhiều lên kéo theo rất nhiều vấn đề phát sinh như:
- Hỏng hóc
- Dữ liệu không còn thống nhất sau khi máy chủ hỏng
- Chương trình sẽ ra sao khi máy chủ hỏng hóc.
- Tắc nghẽn mạng: số lượng máy chủ nhiều → các máy tính nói chuyện với nhau nhiều → tắc nghẽn mạng.
→ Tính toán với nhiều máy tính không hề dễ
Cách để cho các máy tính cùng xử lý (Map-Reduce)
Khi đã tìm được cách đấu nói, vấn đề tiếp theo là lập ra được mô hình xử lý dữ liệu trên cluster hiện tại. Map-Reduce là một giải pháp! Map-Reduce được phát minh bởi các kỹ sư Google để giải quyết bài toán của họ từ hơn 10 năm trước! Map-Reduce giải quyết các vấn đề liệt kê ở trên bằng cách:
- Phân chia dữ liệu thành nhiều block và chia cho nhiều máy tính lưu trữ (đảm bảo tính toàn vẹn và tính sẵn sàng của dữ liệu).
- Chuyển tính toán về nơi có dữ liệu. Ý tưởng chuyển tính toán đến nơi có dữ liệu thực sự là một sự đột phá và đã được đề xuất trong một bài báo của nhà khoa học máy tính Jim Gray từ năm 2003.
- Đưa ra mô hình và giao diện tính toán đơn giản.
Chia dữ liệu thành nhiều Block
Các kỹ sư Google giải quyết bài toán này bằng giải pháp GFS. GFS là một hệ thống quản lý File phân tán với các chức năng giống như hệ thống File bình thường của Linux như: không gian tên (namespace), tính thừa thãi (redundancy), và tính sẵn sàng (availability). Như đã giới thiệu ở bài viết Các giải pháp BigData, HDFS cũng là một một hệ thống quản lý File phân tán.
Đặc điểm của hệ thống File phân tán này là:
- Dùng để quản lý các File có kích thước lớn: kích thước từ trăm GB đến TB
- Dữ liệu ít khi bị cập nhật ở giữa file (kiểu mở file, đến dữa file, cập nhật) mà thường được đọc học ghi vào cuối File (append).
GFS được thiết kế bao gốm 2 module: Chunk Server và Master Server.
Chunk Server làm nhiệu vụ lưu trữ các chunk (hay block) dữ liệu. Mỗi chunk có thể của 1 File hay của file khác. Các Chuck dữ liệu được sao chép giữa các máy chủ khác nhau.
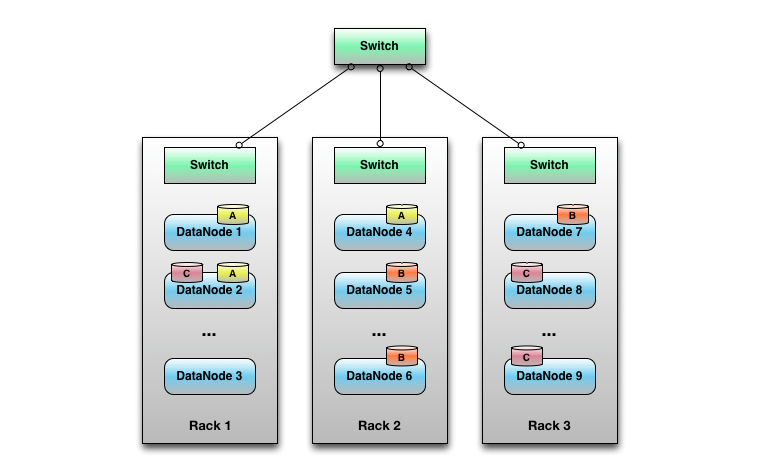
Chunk Server có thể được mình hoạ bởi hình ở trên. Ví dụ ta có file A gồm 3 Chunks, File B gồm 3 Chunk và File C gồm 3 Chunk. Các Chunk sẽ được lưu trữ ở các Chunk Server (DataNode) khác nhau nằm ở các Rack khác nhau.
Mỗi Chunk Server vừa làm nhiệm vụ lưu trữ dữ liệu vừa thực hiện tính toán. Thông thường 1 File sẽ được chia làm các chunks có kích thường từ (64MB đến 128MB) và thường mỗi chunk sẽ được chép 3 bản và lưu ở các máy chủ khác nhau.
Master Server (hay NameNode trong HDFS) làm nhiệm vụ quản lý metadata cho hệ thống File. Cụ thể Master Server sẽ lưu giữ thông tin như File này có bao nhiêu Chunk và mỗi Chunk sẽ được lưu ở máy chủ nào. Dựa vào thông tin metadata này mà thuật toán tính toán sẽ chuyển tính toán về máy chủ có chunk (sẽ trình bày kỹ hơn)
Client truy cập 1 file trên GFS bằng quy trình sau:
- Hỏi master server thông tin File (số lượng Chunk, “vị trí” máy chủ lưu trữ)
- Hỏi máy chủ lưu trữ thông tin của File.
Mô hình tính toán (MapReduce)
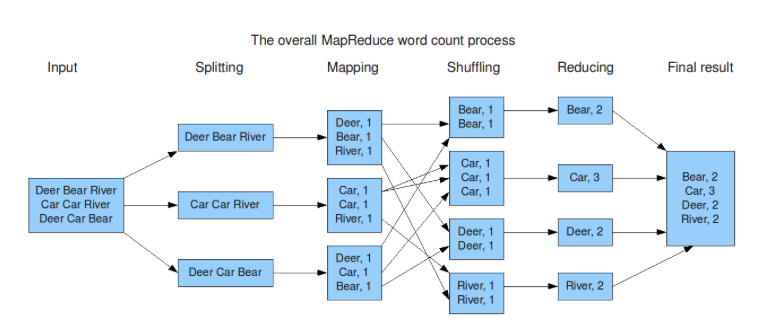
Bài toán word-count (đếm từ) là bài toán dễ hiểu nhất minh hoạ cho MapReduce (MR). Bài toán có những đặc điểm sau:
- File cần đếm rất lớn (quá lớn để có thể được tải lên bộ nhớ chính của 1 máy)
-
Mỗi cặp
quá lớn cho bộ nhớ.
MR chia làm 3 thao tác: Map và Reduce
Map: quét file đầu vào và ghi lại từng bản ghi
Group by Key: sắp xếp và trộn dữ liệu cho mỗi bản ghi sinh ra từ Map
Reduce: tổng hợp, thay đổi hay lọc dữ liệu từ thao tác trước và ghi kết quả ra File.
Hình minh hoạ sau làm rõ các bước và nội dung thực hiện ở mỗi bước.
Về mặt định nghĩa thuật toán, ta có thể mô tả MR như sau:
- Input: dữ liệu dưới dạng Key → Value
-
Lập trình viên viết 2 thủ tục:
-
Map(k, v) →
-
Reduce(k’,
-
Map(k, v) →
Map biến mỗi key k thu được bằng thành cặp
Ví dụ với hình mô tả ở trên thì Map trả về danh sách:
Mô hình này nhìn có vẻ đơn giản nhưng thật sự rất mạnh và có thể giải quyết được rất nhiều bài toán (có dịp mình sẽ cố viết)
Lập lịch và dòng dữ liệu
Sau khi đã có cách đấu nối và phương pháp tính toán, vấn đề tiếp theo cần bàn là tính thế nào, khi nào và ra sao. Map-Reduce có một đặc điểm thú vị là chỉ cần phân chia các File thành các vùng độc lập thì các thủ tục Map không hoàn toàn liên quan đến nhau có thể thực hiện song song.
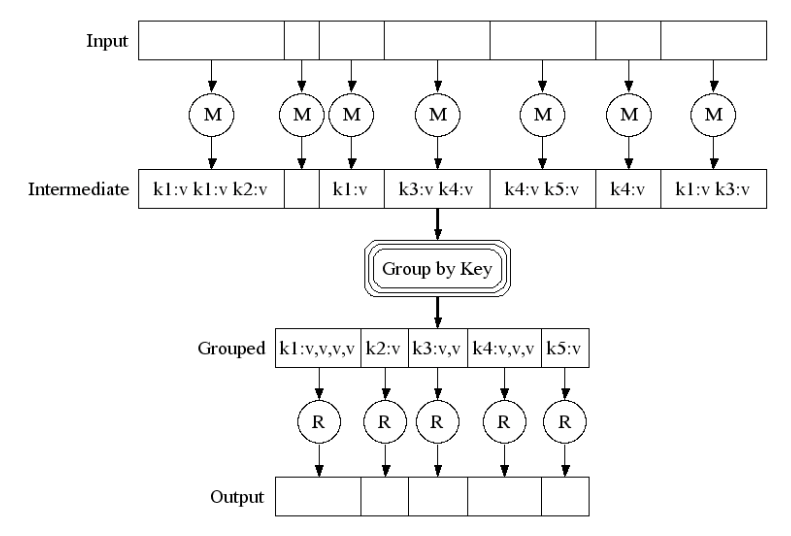
Một File Input có thể được xử lý bởi nhiều Map/Reduce
Như đã viết ở trên Map-Reduce sẽ cố gắng cung cấp giao diện lập trình đơn giản trong khi che dấu những xử lý phức tạp đi. Các xử lý chi tiết phức tạp bao gồm:
- Phân chia dữ liệu
- lập lịch chạy các thủ tục Map/Reduce trên các máy tính
- Thực hiện thủ tục Groupby
- Quản lý hỏng hóc (ví dụ tự động khởi động các thủ tục M/R đang chạy dở thì máy hỏng, quản lý dữ liệu khi máy hỏng)
- Quản lý giao tiếp giữa các máy tính.
Vậy dữ liệu sẽ được lưu truyển thế nào trong 1 quá trình M/R. Về cơ bản Framework lập trình M/R sẽ cố gắng lập lịch cho các thủ tục M/R diễn ra ở các Chunk server có dữ liệu mà thủ tục cần (Chuyển tính toán đến nơi có dữ liệu). Các dữ liệu trung gian trong quá trình M/R sẽ được lưu ở Local FS của các máy chủ đang chạy M/R. Dữ liệu Output từ các M/R sẽ là output cho các M/R khác tổng hợp dữ liệu.
Trong quá trình chạy, một máy tính gọi là Master node phải chịu trách nhiệm quản lý tiến trình cũng như trạng thái các M/R. Khi Map kết thúc, thủ tục này sẽ thông báo trạng thái cũng như đường dẫn file kết quả cho Master để Master biết khởi động Reduce. Node master cũng làm nhiệm vụ ping các máy chủ workers định kỳ để phát hiện hỏng hóc có thể có.
Khi xảy ra lỗi, master sẽ khởi động và tái lập lịch lại các Map/Reduce. Khi Master bị lỗi, toàn bộ hệ thống sẽ lỗi.
Kết luận
Bài viết trình bày 3 vấn đề cơ bản về Map-Reduce
- Distributed File-System – DFS (Hệ thống file phân tán)
- Mô hình tính toán MapReduce
- Lập lịch và luồng dữ liệu
Hy vọng qua bài “chém gió” này, mọi người hiểu rõ hơn về hoạt động của công nghệ 10 năm tuổi này!
Thú nhận: Bạn nào để ý sẽ thấy mình viết bài này theo sườn bài giảng về Map-Reduce trên Coursera hihi. Bạn nào muốn biết rõ hơn về công nghệ này có thể theo dõi bài giảng trên.
Một số tài liệu tham khảo
- https://www.coursera.org/course/mmds
- https://www.mmds.org/
- https://en.wikipedia.org/wiki/Google_File_System
- https://research.google.com/archive/mapreduce.html
- https://hadoop.apache.org/
- Cách viết Map-Reduce
Techtalk via Kipalog